1. docker容器添加额外的网络
- docker 容器配置一个underlay的物理ip
# 获取所有的命名空间
lsns
# 获取网络命名空间`lsns --help`查看具体的每一列代表什么
lsns --type net
# 查看docker的网络隔离命名空间
ls -alh /run/docker/netns
docker run -d --name nginx nginx
# 查看网络命名空间
docker inspect nginx
# 查看当前的ip直接访问测试是否ok 172.17.0.3
# 将某个进程所在的命令空间挂载到指定名字
ip netns attach <name> <pid>
# 查看某个进程所在命名空间
ip netns identify <pid>
# 也可以将具体的命名空间连接到/var/run/netns
# 这里将docker创建的nginx容器具体的网络命名空间aa4fc1e4df42,软连接到ip识别的网络命名空间下
ln -s /run/docker/netns/aa4fc1e4df42 /var/run/netns/busybox
# 这里获取nginx的pid以后直接使用attach的方式
ps -ef|grep nginx
ip netns attacch nginx 3901662
# 增加一个macvlan设备并配置给nginx隔离空间
ip link add macvlan1 link enp0s31f6 type macvlan mode bridge
ip link set dev macvlan1 netns nginx
ip netns exec nginx ip link
# 配置ip并测试网络是否ok
ip netns exec nginx ip link set macvlan1 up
ip netns exec nginx ip route
# 随便选一个空闲的ip分配给macvlan1
ping 172.16.20.120
ip netns exec nginx ip addr add 172.16.20.120/23 dev macvlan1
ip netns exec nginx ip route
# 测试到网关是否ok
ip netns exec nginx ping 172.16.21.254
# 测试访问nginx服务是否ok,页面访问或者直接curl
curl 172.16.20.120
2. 通过underlay路由实现overlay
- 通过给两台主机的隔离网络添加路由实现overlay互通
- node1 物理网卡ip: 192.168.3.2 mac: 52:54:00:09:ef:b4
- node2 物理网卡ip: 192.168.3.3 mac:52:54:00:b9:d4:ba
- node1 overlay :10.0.2.0/24
- node2 ovlary :10.0.3.0/24
2.1 node1 配置
# node1 的操作
# 配置允许转发
# 也可以通过修改/etc/sysctl.conf 永久生效
sysctl -w net.ipv4.ip_forward=1
# 创建网桥(docker会创建一个br-xxx的网桥设备)
docker network create --attachable=true --driver=bridge --subnet=10.0.2.0/24 br0
# 需要检查iptables是否开启允许网络转发一般docker默认会创建,如果没有的话需要开启
# iptables -A FORWARD -s 10.0.2.0/24 -j ACCEPT
# iptables -A FORWARD -d 10.0.3.0/24 -j ACCEPT
# 配置路由,让发往对端的走对端的underlay的ip
ip route add 10.0.3.0/24 via 192.168.3.3 dev enp1s0 onlink
# 启动容器
docker run -d --network=br0 --ip=10.0.2.2 --name=container3 busybox sh -c "while true; do sleep 86400; done"
docker run -d --network=br0 --ip=10.0.2.3 --name=container4 busybox sh -c "while true; do sleep 86400; done"
2.2 node2 配置
# node2 的操作与node1的操作是镜像的
# 开启允许转发
sysctl -w net.ipv4.ip_forward=1
# 创建网桥,注意这里网段
docker network create --driver=bridge --subnet=10.0.3.0/24 br0
# 同样需要检查是否已经放开防火墙
# iptables -A FORWARD -s 10.0.3.0/24 -j ACCEPT
# iptables -A FORWARD -d 10.0.2.0/24 -j ACCEPT
# 配置路由
ip route add 10.0.2.0/24 via 192.168.3.2 dev enp1s0 onlink
# 启动容器
docker run -d --network=br0 --ip=10.0.3.2 --name=container1 busybox sh -c "while true; do sleep 86400; done"
docker run -d --network=br0 --ip=10.0.3.3 --name=container2 busybox sh -c "while true; do sleep 86400; done"
2.3 测试
# 通过ping查看网络是否通
docker exec container2 ping 10.0.2.2
# 可以通过抓包查看,通过在宿主机抓包可以看到出去的包修改了源地址,目标地址没有变,但是目标mac是对端underly的网卡的mac
# 这里利用了二层网络通过mac转发
# 当网络到了对端的时候就会走本地路由,路由到网桥上去
3. 静态vxlan实现overlay网络
3.1 名词解释
- VTEP (VxLAN Tunnel Endpoints): VXLAN隧道端点
- VNI (VXLAN Network Identifier): VXLAN 网络标识符等同于vlan 的id
3.2 Vxlan 点到点实验
- 主机A: 192.168.3.2 主机B: 192.168.3.3 这里可以不是一个网段
- overlay网段10.1.0.0/16
- 这里任务的划分docker的网络主机A:10.1.2.0/24
- 这里任务的划分docker的网络主机B:10.1.3.0/24
3.2.1 主机A操作
# 创建vxlan隧道vtep
ip link add vxlan2 type vxlan \
id 42 \
dstport 4789 \
remote 192.168.3.3 \
local 192.168.3.2 \
dev enp1s0
ip link set dev vxlan2 up
# 创建docker网络
docker network create --driver=bridge --subnet=10.1.0.0/16 vxl0
# 将vxlan桥接到网桥上
ip link set dev vxlan2 master br-11a085318341
# 启动容器
docker run -d --network=vxl0 --ip=10.1.2.2 --name=vxlan-container01 busybox sh -c "while true; do sleep 86400; done"
3.2.2 主机B操作
# 这里相对于A是镜像的擦欧总
# 创建vxlan隧道vtep
ip link add vxlan3 type vxlan \
id 42 \
dstport 4789 \
remote 192.168.3.2 \
local 192.168.3.3 \
dev enp1s0
ip link set dev vxlan3 up
# 创建docker网络
docker network create --driver=bridge --subnet=10.1.0.0/16 vxl0
# 将vxlan桥接到网桥上
ip link set dev vxlan2 master br-11a085318341
# 启动容器
docker run -d --network=vxl0 --ip=10.1.3.2 --name=vxlan-container01 busybox sh -c "while true; do sleep 86400; done"
3.2.3 测试
# nodeA
docker exec vxlan-container01 ping 10.1.3.2
# 可以在虚拟机的宿主机抓对应网桥的包,可以看到vxlan包的具体信息
3.3 Vxlan 组播模式
# 注意这里的id
# 地址是组播地址
ip link add vxlan33 type vxlan \
id 43 \
dstport 4789 \
group 239.1.1.1 \
dev enp1s0
# 这里简单配置一下测试
ip link set dev vxlan33 up
ip addr add 10.10.1.3/24 dev vxlan33
# 对端做镜像配置
4. 使用Vxlan 实现三层overlay
通过路由和proxy_arp实现三层通信,通过加入vxlan实现跨主机的overlay三层 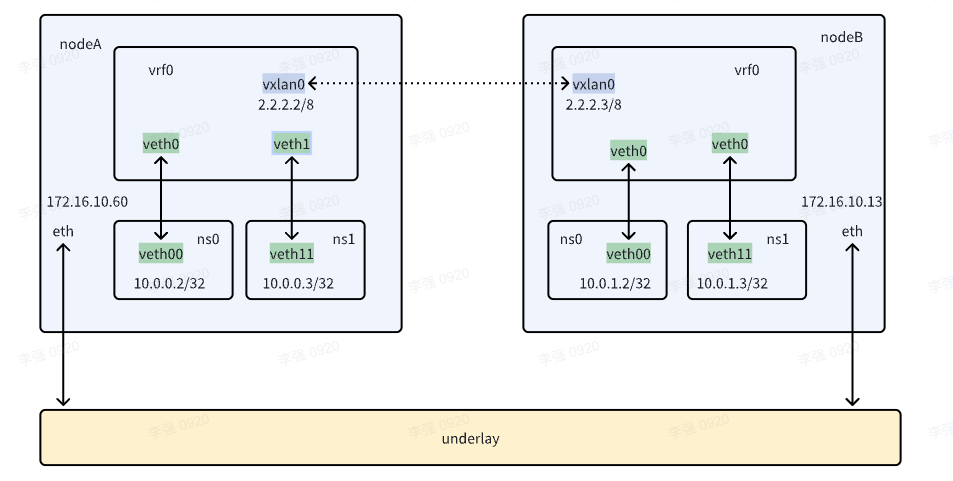
- 准备两台主机,主机A:172.16.10.60 主机B:172.16.10.13
- 在两台主机上创建vrf隔离网络
- 创建隔离netns
- 创建veth网卡对将一端加入vrf
- 创建vrf内路由并开启veth的proxy_arp
- 测试同一个vrf内网络是否能通信
- 创建vxlan加入vrf并创建路由
- 测试跨主机的overlay是否能通信
4.1 nodeA 操作
# 创建vrf和veth
ip link add vrf0 type vrf table 10
ip link set vrf0 up
ip netns ls
ip netns add ns0
ip netns add ns1
ip link show type veth
ip link add veth0 type veth peer name veth00
ip link add veth1 type veth peer name veth11
ip link set veth00 netns ns0
ip link set veth11 netns ns1
ip link set dev veth0 master vrf0
ip link set dev veth0 up
ip link set dev veth1 master vrf0
ip link set dev veth1 up
# 配置ip
ip netns exec ns0 ip a
ip netns exec ns0 ip link set veth00 up
ip netns exec ns0 ip link set lo up
ip netns exec ns0 ip addr add 10.0.0.2 dev veth00
ip netns exec ns1 ip a
ip netns exec ns1 ip link set veth11 up
ip netns exec ns1 ip link set lo up
ip netns exec ns1 ip addr add 10.0.0.3 dev veth11
# 增加默认路由
ip netns exec ns1 ip route
ip netns exec ns1 ip route add 169.254.1.1 dev veth11 scope link
ip netns exec ns1 ip route add default via 169.254.1.1 dev veth11
ip netns exec ns1 ip route
ip netns exec ns0 ip route
ip netns exec ns0 ip route add 169.254.1.1 dev veth00 scope link
ip netns exec ns0 ip route add default via 169.254.1.1 dev veth00
ip netns exec ns0 ip route
# 开启arp代理
cat /proc/sys/net/ipv4/conf/veth0/proxy_arp
echo 1 > /proc/sys/net/ipv4/conf/veth0/proxy_arp
cat /proc/sys/net/ipv4/conf/veth1/proxy_arp
echo 1 > /proc/sys/net/ipv4/conf/veth1/proxy_arp
# 配置路由
ip route show vrf vrf0
ip route add vrf vrf0 10.0.0.2 dev veth0
ip route add vrf vrf0 10.0.0.3 dev veth1
# 到这里应该是可以通vrf0内的路由了
ip netns exec ns1 ping 10.0.0.2
# 配置vxlan
ip link add vxlan0 type vxlan id 100 dstport 4789 local 172.16.10.60 remote 172.16.10.13
ip link show type vxlan
ip -d link show vxlan0
ip link set dev vxlan0 master vrf0
ip link set dev vxlan0 up
ip addr add 2.2.2.2/8 dev vxlan0
echo 1 > /proc/sys/net/ipv4/conf/vxlan0/proxy_arp
cat /proc/sys/net/ipv4/conf/vxlan0/proxy_arp
ip link show master vrf0
ip route show vrf vrf0
# 添加对端的网络路由到vrf
ip route add vrf vrf0 10.0.1.2 dev vxlan0
ip route add vrf vrf0 10.0.1.3 dev vxlan0
ip route show vrf vrf0
sysctl -w net.ipv4.conf.all.rp_filter=0
4.2 nodeB 操作
# 创建vrf和veth
ip link add vrf0 type vrf table 10
ip link set vrf0 up
ip netns ls
ip netns add ns0
ip netns add ns1
ip link show type veth
ip link add veth0 type veth peer name veth00
ip link add veth1 type veth peer name veth11
ip link set veth00 netns ns0
ip link set veth11 netns ns1
ip link set dev veth0 master vrf0
ip link set dev veth0 up
ip link set dev veth1 master vrf0
ip link set dev veth1 up
# 配置ip
ip netns exec ns0 ip a
ip netns exec ns0 ip link set veth00 up
ip netns exec ns0 ip link set lo up
ip netns exec ns0 ip addr add 10.0.1.2 dev veth00
ip netns exec ns1 ip a
ip netns exec ns1 ip link set veth11 up
ip netns exec ns1 ip link set lo up
ip netns exec ns1 ip addr add 10.0.1.3 dev veth11
# 增加默认路由
ip netns exec ns1 ip route
ip netns exec ns1 ip route add 169.254.1.1 dev veth11 scope link
ip netns exec ns1 ip route add default via 169.254.1.1 dev veth11
ip netns exec ns1 ip route
ip netns exec ns0 ip route
ip netns exec ns0 ip route add 169.254.1.1 dev veth00 scope link
ip netns exec ns0 ip route add default via 169.254.1.1 dev veth00
ip netns exec ns0 ip route
# 开启arp代理
cat /proc/sys/net/ipv4/conf/veth0/proxy_arp
echo 1 > /proc/sys/net/ipv4/conf/veth0/proxy_arp
cat /proc/sys/net/ipv4/conf/veth1/proxy_arp
echo 1 > /proc/sys/net/ipv4/conf/veth1/proxy_arp
# 配置路由
ip route show vrf vrf0
ip route add vrf vrf0 10.0.1.2 dev veth0
ip route add vrf vrf0 10.0.1.3 dev veth1
# 到这里应该是可以通vrf0内的路由了
ip netns exec ns1 ping 10.0.1.2
# 配置vxlan
ip link add vxlan0 type vxlan id 100 dstport 4789 local 172.16.10.13 remote 172.16.10.60
ip link show type vxlan
ip -d link show vxlan0
ip link set dev vxlan0 master vrf0
ip link set dev vxlan0 up
ip addr add 2.2.2.3/8 dev vxlan0
echo 1 > /proc/sys/net/ipv4/conf/vxlan0/proxy_arp
cat /proc/sys/net/ipv4/conf/vxlan0/proxy_arp
ip link show master vrf0
ip route show vrf vrf0
# 添加对端的网络路由
ip route add vrf vrf0 10.0.0.2 dev vxlan0
ip route add vrf vrf0 10.0.0.3 dev vxlan0
ip route show vrf vrf0
sysctl -w net.ipv4.conf.all.rp_filter=0
4.3 测试
# nodeA
ip netns exec ns0 ping 10.0.1.2
# nodeB
ip netns exec ns0 ping 10.0.0.2
5. ipip隧道搭建overlay网络
- 普通的 IPIP 隧道,就是在报文的基础上再封装成一个 IPv4 报文
- 使用隧道搭建overlay网络
- 需要使用内核ipip modprobe ipip
- 开启ip_forward echo 1 > /proc/sys/net/ipv4/ip_forward 确认cat /proc/sys/net/ipv4/ip_forward
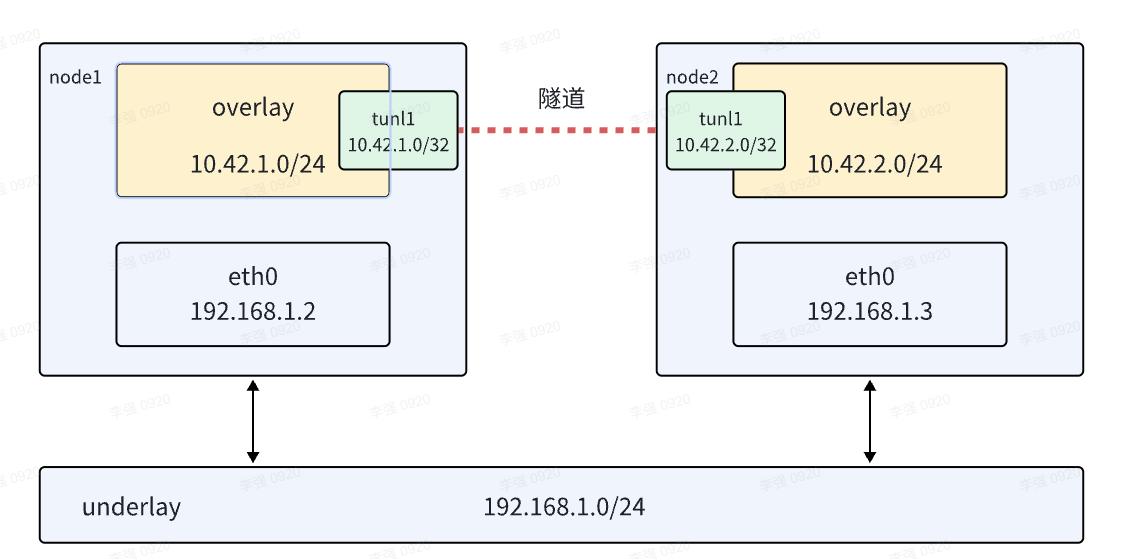
5.1 nodeA 上操作
# 设置网桥
ip link add name br0 type bridge
ip addr add 10.20.2.1/24 dev br0
ip link set dev br0 up
# 设置tunl
modprobe ipip
ip tunnel add tunl1 mode ipip remote 192.168.3.3 local 192.168.3.2
ip link set tunl1 up
# 配置路由让对端的子网走隧道
ip route add 10.20.3.0/24 via 192.168.3.3 dev tunl1 onlink
# 配置隔离网络
ip link add veth0 type veth peer veth00
ip link set dev veth0 up
ip link set dev veth0 master br0
# 配置隔离netns的网络
ip netns ls
ip netns add ns1
ip link set dev veth00 netns ns1
ip netns exec ns1 ip addr add 10.20.2.2/24 dev veth00
# 配置隔离的路由默认走网桥
ip netns exec ns1 ip route add default via 10.20.2.1 dev veth00
# 查看一下路由对不对
ip netns exec ns1 ip route
5.2 nodeB 上做镜像操作
# 设置网桥
ip link add name br0 type bridge
ip addr add 10.20.3.1/24 dev br0
ip link set dev br0 up
# 设置tunl
modprobe ipip
ip tunnel add tunl1 mode ipip remote 192.168.3.2 local 192.168.3.3
ip link set tunl1 up
# 配置路由让对端的子网走隧道
ip route add 10.20.2.0/24 via 192.168.3.2 dev tunl1 onlink
# 配置隔离网络
ip link add veth0 type veth peer veth00
ip link set dev veth0 up
ip link set dev veth0 master br0
# 配置隔离netns的网络
ip netns ls
ip netns add ns1
ip link set dev veth00 netns ns1
ip netns exec ns1 ip addr add 10.20.3.2/24 dev veth00
# 配置隔离的路由默认走网桥
ip netns exec ns1 ip route add default via 10.20.3.1 dev veth00
# 查看一下路由对不对
ip netns exec ns1 ip route
5.3 测试
# 在A 上面ping B上的子网
ip netns exec ns1 ping 10.20.3.2